LR法
LR法またはLR構文解析器とは、文脈自由文法の構文解析手法/構文解析器である。LR法では、入力を左(Left)から右に読んでいき、右端導出(Rightmost derivation)を行う。このためLRと名づけられている。「LR(k)」といった場合、k は、消費をともなうことなく「先読み」が進められる入力記号の最大数を意味する。通常、k は 1 であり、その場合省略されることが多い。LR(k)の構文解析器が対応する文脈自由文法も LR(k) と呼ばれる。
目次
1 概要
2 LR法の構成
2.1 アクション表とGOTO表
2.2 構文解析アルゴリズム
3 LR(0) 構文解析表の作成
3.1 アイテム
3.2 アイテム集合
3.3 アイテム集合のクロージャ
3.4 強化された文法
3.5 到達可能なアイテムの探索と遷移
3.6 アクション表とGOTO表の構築
3.6.1 LR(0) と SLR/LALR法
3.7 構築した表内での衝突
4 参考文献
概要
LR法はいわゆるボトムアップ構文解析を行う。つまり、葉から始めて最上位の構文要素にたどり着く。
ほとんどのプログラミング言語の文法は LR(1) で表されるため、LR法はコンパイラがソースコードの構文を解析する際によく使われる。
一般にLR構文解析器と言った場合、文脈自由文法に基づいた特定の言語を理解する特定の構文解析器を意味していることが多い。
LR法には次のような利点がある:
- 多くのプログラミング言語がLR法(およびそれを一部改変したもの)で構文解析できる。例外として、C++とPerlがある。
- LR法の実装は非常に効率的である。
- 入力を左から右に読んでいく構文解析器の中では、LR構文解析器は構文エラーを可能な限り素早く検出できる。
LR法には次のような欠点がある:
LL法に比べ、コンパイルエラー時のエラーメッセージを適切に出しにくい。
LR構文解析器を1から書くのは難しく、パーサジェネレータを使って生成するのが一般的である。構文解析表の生成手法の違いにより、単純LR法(SLR)、LALR法、正規LR法に分類される。後者ほど大規模な文法を扱える(LALR法はSLR法より強力で、正規LR法はLALR法より強力である)。yaccはLALR法による構文解析器を生成する。
LR法の構成
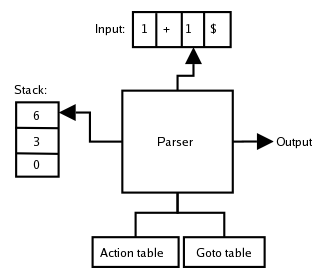
表に基づいたボトムアップ構文解析器の構成を右図に示す。構文解析器には、「入力バッファ」、状態を保持するための「スタック」、次に遷移すべき状態や現在の状態で読み込んだ終端記号や非終端記号に適用すべき文法規則を示す「アクション表」と「GOTO表」を持つ。これらの動きを示すため、以下の簡単な文法を使って説明する:
- (1) E → E * B
- (2) E → E + B
- (3) E → B
- (4) B → 0
- (5) B → 1
アクション表とGOTO表
この文法のための2つの LR(0) 構文解析表は次のようになる:
| アクション | GOTO | |||||||
| 状態 | * | + | 0 | 1 | $ | E | B | |
| 0 | | s1 | s2 | 3 | 4 | |||
| 1 | r4 | r4 | r4 | r4 | r4 | | ||
| 2 | r5 | r5 | r5 | r5 | r5 | | ||
| 3 | s5 | s6 | acc | | | |||
| 4 | r3 | r3 | r3 | r3 | r3 | | | |
| 5 | | s1 | s2 | | 7 | |||
| 6 | | s1 | s2 | | 8 | |||
| 7 | r1 | r1 | r1 | r1 | r1 | | | |
| 8 | r2 | r2 | r2 | r2 | r2 | | | |
アクション表は状態と終端記号でインデックス付けされている(特殊な終端記号 $ は入力ストリームの終わりを示す)。各マスには以下のようなアクションが記述されている:
shift(sn): 次の状態遷移先を n で示す。
reduce(rm): m番の文法規則を実行する。
accept(acc): 入力ストリームにある文字列を受容する。
GOTO表は状態と非終端記号でインデックス付けされており、各マスには非終端記号を解釈し終えたときの次に遷移すべき状態を示す。
構文解析アルゴリズム
LR法のアルゴリズムは次のように動作する:
- スタックは [0] で初期化される。現在状態は常にスタックのトップにある状態で表される。
- 現在状態と入力にある記号からアクション表を参照する。ここで4つのケースがある:
- sn に従って状態遷移する。
- 現在の終端記号を入力ストリームから取り除く。
- 状態 n をスタックにプッシュし、それを現在状態とする。
- rm に従って文法規則を適用する。
- 番号 m を出力ストリームに書き出す。
m 番の規則の右側にある各記号についてスタックから状態を削除する(例えば E * B なら3個ポップする)。- その時点のスタックのトップを状態とし、それと m 番の文法規則の左側からGOTO表を参照し、そこにある状態をスタックにプッシュして新たな状態とする。
- 受容の場合、文字列の構文解析が完了。
- アクションが指定されていない場合、文法エラーを報告する。
- sn に従って状態遷移する。
- 上のステップを「受容」となるか「文法エラー」となるまで繰り返す。
このアルゴリズムが何故うまく動作するのかを説明するため、文字列 "1 + 1" をこの構文解析器で解析する例を示す。下記の表はその処理の各ステップを示したものである。状態はスタックのトップで示されている(一番右の値)。次のアクションは上にあるアクション表を参照して決めている。また、入力の最後を示すため、 $ が追加されている。
| 状態 | 入力ストリーム | 出力ストリーム | スタック | 次のアクション |
|---|---|---|---|---|
| 0 | 1+1$ | [0] | Shift 2 | |
| 2 | +1$ | [0,2] | Reduce 5 | |
| 4 | +1$ | 5 | [0,4] | Reduce 3 |
| 3 | +1$ | 5,3 | [0,3] | Shift 6 |
| 6 | 1$ | 5,3 | [0,3,6] | Shift 2 |
| 2 | $ | 5,3 | [0,3,6,2] | Reduce 5 |
| 8 | $ | 5,3,5 | [0,3,6,8] | Reduce 2 |
| 3 | $ | 5,3,5,2 | [0 3] | Accept |
構文解析を開始したとき、常に状態 0 から始まる。スタックは次のようになっている:
- [0]
構文解析器が最初に見る入力記号は '1' であり、アクション表を参照すると状態 2 への遷移が指示されているので、スタックが次のようになる:
- [0 '1' 2]
スタックのトップは右端である。なお、説明のために状態遷移の原因となった記号(ここでは '1')をその前に記している。もちろん、本当のスタックにはこのような記号はプッシュされない。
状態 2 ではアクション表によれば、次の入力記号が何であれ、5 番の文法規則を適用しなければならない。これはつまり、5 番の規則の右辺を認識したことを示す。そこで、出力ストリームに 5 を書き出し、スタックから1個の状態をポップし、GOTO表から(状態 0 で非終端記号 B)状態 4 をスタックにプッシュする。結果としてスタックは次のようになる:
- [0 B 4]
状態 4 の場合、アクション表を見ると文法規則 3 番の適用をしなければならない。そこで出力ストリームに 3 を書き出し、スタックから1個の状態をポップして、GOTO表から(0、E)状態 3 を新たにプッシュする。スタックは次のようになる:
- [0 E 3]
次の入力記号を見ると '+' であり、アクション表によれば状態 6 に遷移しなければならない。
- [0 E 3 '+' 6]
このスタックは有限オートマトンの動作履歴のようなものであり、現在は非終端記号 E を読んだ直後に終端記号 '+' を読んだ状態を示している。このオートマトンの状態遷移表はアクション表の shift 指定と GOTO表から構成される。
次の入力記号は '1' なので、アクション表から状態 2 への遷移となる:
- [0 E 3 '+' 6 '1' 2]
前に '1' を読んだときと同様、文法規則の適用により B に還元され、スタックは次のようになる:
- [0 E 3 '+' 6 B 8]
これは有限オートマトンが、非終端記号 E と 終端記号 '+' と 非終端記号 B を順に読んだ状態である。状態 8 では常に規則 2 番を適用する。従ってスタック上の3個の状態がその文法規則の右辺の3個の記号に対応する。
- [0 E 3]
最後に '$' を入力ストリームから読むと、現在状態は 3 なので「受容」すなわち構文解析完了である。以上から出力ストリームに書かれる規則番号の列は [5, 3, 5, 2] となる。これは "1 + 1" という文字列を右端導出する際の適用規則列を逆転させたものと同じである。
LR(0) 構文解析表の作成
アイテム
これらの構文解析表の作成は「LR(0)アイテム」(ここでは単にアイテムと呼ぶ)の記法に基づいている。アイテム記法とは、文法規則の右辺の各所に特別なドット記号を付与したものである。例えば、規則 E → E + B からは次の4つのアイテムが得られる:
- E → • E + B
- E → E • + B
- E → E + • B
- E → E + B •
A → ε という規則からは A → • というアイテムだけが得られる。これらの規則から構文解析器の状態を記述する。例えば、アイテム E → E • + B は、E を認識した状態で次に '+' を読み込み、さらに B に対応する文字列がそれに続くことを期待していることを示す。
アイテム集合
一般に次に適用される文法規則は事前にわからないので、単一のアイテムだけで構文解析器の状態を特定することはできない。例えば、E → E * B という規則から得られるアイテム E → E • * B とアイテム E → E • + B は共に非終端記号 E を読んだ後で適用可能である。従って構文解析器の状態はアイテムの集合によって特徴付けられる。この例の場合、集合は { E → E • + B, E → E • * B } となる。
アイテム集合のクロージャ
E → E + • B のように非終端記号の前にドットのあるアイテムは、構文解析器が次に非終端記号 B を構文解析すべきであることを示している。構文解析中に適用が可能な全ての規則をアイテム集合に含めるため、ここでは B 自体の構文解析を表すアイテム集合も含めなければならない。すなわち B → 1 や B → 0 といった規則がある場合、アイテム B → • 1 や B → • 0 をアイテム集合に含めるということである。これを一般化して定式化すると次のようになる:
A → v•Bw という形式のアイテムがアイテム集合内にあり、文法に B → w' という規則がある場合、アイテム B → • w' をアイテム集合に含めなければならない。
これをアイテム集合全体に適用して、全ての非終端記号の前のドットに関して同様の処置を施してアイテム集合を特定する。ここで、構文解析のある特定の状態を与えるアイテム集合を「クロージャ」と呼び、clos(I) と表記する。ここで、I はアイテム集合である。ただし、構文解析表では初期状態から到達可能な状態に関するものしか考慮されない。
強化された文法
異なる状態間の遷移を決定する前に、文法に次の規則を追加して強化するのが一般的である。
- (0) S → E
ここで、S は新たに導入された開始記号であり、E は従来の開始記号である。この規則は構文解析器が入力文字列を受容した際に適用される。
ここでは上述の例の文法を強化して使用する。
- (0) S → E
- (1) E → E * B
- (2) E → E + B
- (3) E → B
- (4) B → 0
- (5) B → 1
この強化された文法についてアイテム集合とそれらの間の遷移を決定する。
到達可能なアイテムの探索と遷移
構文解析表作成の第一段階は、アイテム集合クロージャ間の遷移の決定である。これはちょうど終端記号も非終端記号も読み込む有限オートマトンを検討する要領で決定できる。このオートマトンの開始状態は常に追加された規則から得られるアイテム S → • E で表される状態である。
- アイテム集合 0
- S → • E
- + E → • E * B
- + E → • E + B
- + E → • B
- + B → • 0
- + B → • 1
アイテムの前に付与されたプラス記号は、そのアイテムがクロージャに追加されたことを意味している。'+'記号が付与されていない初期アイテムをそのアイテム集合の「核」と言う。
初期状態 (S0) から始めて、ここから到達できる全状態を決定する。まず、各アイテムの右辺でドットの次にある記号に注目する。この場合、終端記号 '0' と '1'、および非終端記号 E と B が現われている。記号 x からアイテム集合を見つけるため、次の手続きを実行する:
- 現在のアイテム集合内の各アイテムで何らかの記号 x の前にドットのある全アイテムの集合 S を求める。
S 内の各アイテムについて、ドットを x の次の位置に移す。- 結果として生じたアイテム集合を閉じる。
終端記号 '0' について、この手続きを行うと次のようになる:
- アイテム集合 1
- B → 0 •
終端記号 '1' については次の通り:
- アイテム集合 2
- B → 1 •
非終端記号 E では次のようになる:
- アイテム集合 3
- S → E •
- E → E • * B
- E → E • + B
非終端記号 B については次の通り:
- アイテム集合 4
- E → B •
これらのクロージャではドットの後に非終端記号がないため、新たなアイテムが追加されていない。この手続きを新たなアイテム集合がなくなるまで続ける。アイテム集合1, 2, 4 はドットの後に記号がないため、ここで終わりである。アイテム集合 3 についてはドットの後に終端記号 '*' と '+' がある。'*' についての遷移は次のアイテム集合で表される。
- アイテム集合 5
- E → E * • B
- + B → • 0
- + B → • 1
同様に '+' については次の通り:
- アイテム集合 6
- E → E + • B
- + B → • 0
- + B → • 1
アイテム集合 5 では、終端記号 '0' と '1'、非終端記号 B を考慮する必要がある。終端記号については既出のアイテム集合 1 と 2 が対応する。非終端記号 B については次のような遷移が導かれる:
- アイテム集合 7
- E → E * B •
アイテム集合も同様に終端記号 '0' と '1'、非終端記号 B を考慮する必要がある。また、同様に終端記号については既出のアイテム集合 1 と 2 が対応する。非終端記号 B については次のような遷移が導かれる:
- アイテム集合 8
- E → E + B •
これらのアイテム集合もドットの後に記号がないので、アイテム集合はこれで全部である。これらから、オートマトンの状態遷移表は次の通りとなる:
| アイテム集合 | * | + | 0 | 1 | E | B |
|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | ||
| 1 | ||||||
| 2 | ||||||
| 3 | 5 | 6 | ||||
| 4 | ||||||
| 5 | 1 | 2 | 7 | |||
| 6 | 1 | 2 | 8 | |||
| 7 | ||||||
| 8 |
アクション表とGOTO表の構築
この表とアイテム集合から、アクション表とGOTO表を次のように構築する:
- 非終端記号に関する列はGOTO表に転記される。
- 終端記号に関する列はアクション表の shift アクションとして転記される。
- 入力の終わりを示す '$' の列をアクション表に追加し、アイテム S → E • を含むアイテム集合に対応するマスに acc を書き込む。
- アイテム集合 i が A → w • という形式のアイテムを含み、対応する文法規則 A → w の番号 m が m > 0 なら、状態 i に対応するアクション表の行には全て reduce アクション rm を書き込む。
この手続きによって前掲のアクション表とGOTO表が作成できる。
LR(0) と SLR/LALR法
上記手続きのステップ4 だけが reduce アクションを生成する。つまり、reduce アクションは必ずアクション表の1つの行で共通となるため、次の入力記号が何であっても文法規則による還元が起きる。これは LR(0) の構文解析表の特徴であり、適用すべき文法規則を決定する前に先読みをしない方式であるためである。あいまいさを排除するために先読みが必要となる文法では、1つの行に複数種類の reduce アクションが存在する可能性があり、上記手続きではそのような表を作成できない。
SLR法やLALR法のようなより洗練された方式では行全体が同じ reduce アクションとはならないような表構築手続きを実施する。つまり、これらの構文解析では LR(0) よりも適用可能な文法の範囲が広い。
構築した表内での衝突
ところで、構築されたオートマトンは常に決定性オートマトンである。しかし、reduce アクションを表に追記しようとすると、1つのマスに shift アクションと reduce アクションが共に存在してしまう場合がある。これは shift-reduce 衝突と呼ぶ。あるいは、2つの reduce アクションが衝突する場合もある。これを reduce-reduce 衝突と呼ぶ。しかし、これが発生するということは、その文法が LR(0) では扱えないことを示している。
非常に単純な LR(0) で扱えない文法(shift-reduce衝突が発生する)の例を示す。
- (1) E → 1 E
- (2) E → 1
ここから次のようなアイテム集合が得られる:
- アイテム集合 1
- E → 1 • E
- E → 1 •
- + E → • 1 E
- + E → • 1
このアイテム集合と終端記号 '1' の交差するマスには、状態 1 への shift アクションと規則 2 の reduce アクションが対応するため、shift-reduce 衝突が発生する。
非常に単純な LR(0) で扱えない文法(reduce-reduce衝突が発生する)の例を示す。
- (1) E → A 1
- (2) E → B 2
- (3) A → 1
- (4) B → 1
この場合、次のようなアイテム集合が得られる:
- アイテム集合 1
- A → 1 •
- B → 1 •
この場合、各アイテムがそれぞれ文法規則 3 と 4 に対応しているため、reduce-reduce 衝突が発生する。
これらの例では、非終端記号 A の Follow-set(LL法参照)を使用して、A の還元規則を使うかどうかを決定すればよい。つまり、入力の次の記号が A の Follow-set にある場合だけ、規則 A → w を適用する。この方式を単純LR法と呼ぶ。
参考文献
Compilers: Principles, Techniques, and Tools, Aho, Sethi, Ullman, Addison-Wesley, 1986. ISBN 0-201-10088-6
- 原田憲一 訳、『コンパイラ—原理・技法・ツール<1>』サイエンス社、1990年。ISBN 4-7819-0585-4
- 原田憲一 訳、『コンパイラ—原理・技法・ツール<2>』サイエンス社、1990年。ISBN 4-7819-0586-2
- 原田憲一 訳、『コンパイラ—原理・技法・ツール<1>』サイエンス社、1990年。ISBN 4-7819-0585-4
- Internals of an LALR(1) parser generated by GNU Bison


