マルチコア
この記事は検証可能な参考文献や出典が全く示されていないか、不十分です。 出典を追加して記事の信頼性向上にご協力ください。(2015年12月) |
マルチコア (Multiple core, Multi-core) は、1つのプロセッサ・パッケージ内に複数のプロセッサ・コアを搭載する技術であり、マルチプロセッシングの一形態である。
外見的には1つのプロセッサでありながら論理的には複数のプロセッサとして認識されるため、同じコア数のマルチプロセッサと比較して実装面積としては省スペースであり、プロセッサコア間の通信を高速化することも可能である。主に並列処理を行わせる環境下では、プロセッサ・チップ全体での処理能力を上げ性能向上を果たすために行われる。このプロセッサ・パッケージ内のプロセッサ・コアが2つであればデュアルコア (Dual-core)、4つであればクアッドコア (Quad-core)、6つであればヘキサコア (Hexa-core)、8つは伝統的にインテルではオクタルコア (Octal-core) 、AMDではオクタコア (Octa-core)と呼ばれるほか、オクトコア (Octo-core) とも呼ばれる。さらに高性能な専用プロセッサの中には十個以上ものコアを持つものがあり、メニーコア (Many-core) と呼ばれる[1]。
なお、従来の1つのコアを持つプロセッサはマルチコアに対してシングルコア (Single-core) とも呼ばれる。
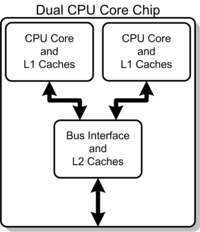
シングルダイ・マルチコアの一例の概念図。この場合、プロセッサ・コアとレベル1キャッシュが2つあり、レベル2キャッシュは2つのコアと共有される。
目次
1 概要
2 用語
3 背景
3.1 複数CPUの実装
3.2 発熱と消費電力の問題
3.3 クロックの限界
3.4 高速処理の専用回路の限界
3.5 処理性能の向上策
4 マルチコア・プロセッサの歴史
5 マルチコア・プロセッサの技術
5.1 ホモジニアスとヘテロジニアス
5.2 電力管理
5.3 メモリー・ボトルネックの解消
5.4 冗長構成
6 プロセッサ例
6.1 汎用プロセッサ
6.2 専用プロセッサ
7 注釈
8 関連項目
概要
マルチコアはシングルコアに対し、プロセスルールが同じであれば、実装したプロセッサ・コア数に比例してダイが大きくなる。面積が増えると、級数的に製造不良が増えるなど製造の面での難度が上る(歩留まりが悪化する)。
並列コンピューティングに対応したプログラミングが必要なため、ソフトウェアの開発は難しくなるが、OSやミドルウェアなどが並列処理の支援を行うことでソフトウェア開発は容易なものとなる場合がある。既にマルチプロセッサ対応しているシングルコア・プロセッサを基にする、マルチコア・プロセッサの製品化は論理設計を省略できるため比較的簡単である。
性能が要求されるワークステーション、サーバ分野はもとより、パーソナルコンピュータ (PC) でも、高消費電力と廃熱処理(および冷却に伴う騒音対策)などによる制約や、クロック周波数向上対効果の停滞などにより、この技術へのシフトが進んでいる。
マルチコア・プロセッサは消費電力低減と発熱抑制を目的に、各コアごとに動作電圧やクロック・スピードの可変制御を行ったり、休止状態を含む動作状態の制御を行っている製品もある。コアごとに複数の電圧で給電するシステムが別途必要となるため、単一電圧に比して設計・実装・製造難易度は高い。
マルチコア・プロセッサに似た技術に、同時マルチスレッディング (Simultaneous multi-threading, SMT) がある。これは1つのプロセッサを外部から2つ以上に見せるという点では同じだが、実際に存在しているコアは1つ、すなわちシングルコアであるという点でマルチコア技術とは根本的に異なる。
用語
効果的に説明するために、まず使用する用語を示す。
- ダイ (Die)
シリコンウェハー上に半導体回路を作り、四角に切り出したもの。ベア・チップやペレットとも呼ばれる。ダイはプロセッサ・パッケージ(CPUパッケージ)と呼ばれる覆いで封止されている。プロセッサはパッケージ化によって、基板との接点、ヒートスプレッダ、コンデンサ、抵抗などが一体となっている。- 半導体産業ではプロセス済みのウェハーやダイの生産までが上流工程であり、テストとパッケージ封入が下流工程になる。大手半導体企業で自社生産としている場合でも下流工程はアウトソーシングしていることがある。シリコンウェハーは無塵環境で製造されるが、不純物等の影響で不良箇所の発生が避けられない。ダイ上のどこか一箇所にでも不良があれば製品にはならないため、プロセスルールの微細化による回路の縮小でダイサイズを縮小し、シリコンウェハーからの切り出しを細分化して数を増やせば、ウェハー生産数に対するダイ不良品の数を減らすことができ、利益率が上がる。

Cell Broadband Engineのダイ

AMD 486 DX 2 66 MHzのパッケージ裏面のカバーを外した様子。中央の黒と緑の部分がダイ。


- コア (Core)
- コアとは、プロセッサ・ダイ上に作成されるプロセッサ回路の中核部分で、「キャッシュメモリ」を除く半導体回路部分。ただし、他のコアとは共有しない、コアごとのキャッシュメモリはコアに含める事がある。多くの場合、プロセッサ・ダイはコア、キャッシュメモリ、ボンディング・パッド等の接続部から構成される。

VIA Isaiahのダイの構成。おおまかに、上半分がキャッシュで下半分にコアが配置されている様子がわかる。

Quad-Core AMD Opteronのダイ。Quad-Coreでホモジニアスマルチコアなので、おなじパターンの回路が4つある。


- サブストレート
- ダイを載せて外部接続ピンなどの外力から守るデジタル半導体の主要構成部材の1つ。MCM (Multi-Chip Module) やMCP (Multi Chip Package) の場合には1つのサブストレートに複数のダイが載る。
- チップ (Chip)
- いくぶん不明瞭な意味で、半導体部品を意味する。ダイやペレットを指す場合もある。また、表面実装技術 (Surface mount technology, SMT) の受動部品を指す場合もある。
背景
ポラックの法則では、プロセッサを構成するトランジスタ数を2倍にしても処理能力は2{displaystyle {sqrt {2}}}倍(約1.4倍)にとどまるとされている。一方で、消費電力はトランジスタ数に比例する。この法則によれば2倍のコストで1.4倍のリターンしか得られず、プロセッサ当りのトランジスタ数を増やすことは非効率となる。

スーパーコンピュータの領域ではより早くからスカラー演算能力の限界として認識されていたシングルCPUによる演算能力向上の限界は、1990年代末頃からはPCやサーバー用の分野でも現実のものとして認識されはじめた。2000年代の中頃にはシングルコアでの処理性能の向上手法よりマルチコアによる向上を図った製品が登場するようになった。
以下にマルチコアが登場した背景について示す。
複数CPUの実装
大型コンピュータやスーパーコンピュータでは、1つの半導体パッケージに複数の汎用プロセッサ・コアを封入することは早くから行われていた。
サーバ用途でのパーソナルコンピュータ類似製品では1990年代中頃から、マザーボード上に複数のプロセッサを実装し並列処理させる対称型マルチプロセッシング (Symmetric multi-processing, SMP) と呼ばれるソリューションが現れていた。こういったマザーボードにマルチコアCPUを装着して、2x2=4 や 2x4=8 といった多数のマルチコア環境が現れている。
発熱と消費電力の問題
1990年代中頃からラップトップパソコンでの「腿(もも)が熱い」という発熱への不満やPCの放熱ファンの騒音が問題として認識され始めた。将来の汎用プロセッサは、製造プロセスの微細化によるリーク電流の増加や、処理能力向上を目的とした動作クロックの高速化によって、消費電力がますます増大していくことが予想された。当時の汎用プロセッサ処理速度の向上手法のままでは、汎用プロセッサのダイ温度が非現実的なまでに高温となり、冷却機構の物理的な限界から性能向上が頭打ちになることもまた予想された。2000年前後から一般ユーザー向けのPCでも水冷式の製品が販売されはじめた。
クロックの限界
2001年からは1GHzを越えるCPUクロックが一般的となり、2010年現在では5GHz前後まで伸びた。しかし、1GHzの1サイクルの時間内では、光速度でも30cmしか伝播できない物理法則の壁がある。そのため、今後さらにクロックが高速化されて5GHz以上や10GHzになれば従来のLCによる伝播遅延に加えて、光速度の7割程度の電気信号そのものの伝播の遅さも無視できなくなってくる。
高速処理の専用回路の限界
現在の汎用プロセッサ内部の処理機構がスーパースカラ機構などにより既に高度に高速処理への最適化がなされている。たとえば命令の先読みによって投機実行と呼ばれる、本当に実行が必要かまだ決まらない内から前もって次の処理を実行してしまうという動作を常に行う、汎用プロセッサの外部に主メモリがあるにもかかわらず汎用プロセッサ上にキャッシュ・メモリーが3段階にも用意されている、さらにプリフェッチ・キューまでが用意されているといった具合である。他にもスーパーパイプライン、VLIW、アウト・オブ・オーダー実行等がある。これらの高速処理に欠かせない汎用プロセッサの回路は、それぞれがほんの少しだけ処理の高速化に貢献している回路であり、これ以上同様の付加回路を汎用プロセッサに追加してもそれほどの処理の高速化には貢献しないと予測される。
処理性能の向上策
マルチコア・プロセッサによってプロセッサ・コア数を増やした場合、OSやソフトウェアの対応により、システム全体の処理性能を向上させられることから、これら発熱とクロックの限界への解決策になる。
実際に今日のPCは動画や音楽データの再生やエンコードのように、マルチスレッドで性能向上を期待できる用途に使われることが増えている。
さらに、バックグラウンドで音楽を再生したりウイルスのチェックを行いながら、メールやWeb閲覧、文書作成、ゲームを楽しむことなどが行われており、複数のアプリケーションや多数のスレッドが実行される環境になっているため、マルチスレッドに対応するアプリケーションソフトウェアを利用していなくても、マルチコアの利点を享受することができる。
マルチコア・プロセッサの歴史
1999年、IBMは商用サーバ向けプロセッサでデュアルコアのPOWER4を発表し、CPUのマルチコア化をリードした。2004年5月にはインテルが従来のPentium 4の高速版でシングルコアCPUの開発コード「Tejas」の開発中止を決定したことが伝えられた。同じ頃、AMDも同社の計画から次世代のK9・K10などシリーズ以降の高速版CPUの開発を全て中止した。なお現在では、K8シリーズをマルチコア化の強化という新たな方向性で製品化したものをK10としている。
2005年になって、AMDは当初から消費電力を抑えマルチコア化を見越したK8アーキテクチャの設計を行い、デュアルコア製品の提供を開始した。製品名はDual-Core OpteronとAthlon 64 X2(→Athlon X2)である。インテルは、マルチコアCPUの市場投入の出遅れをカバーするために、単純に2つのCPUのダイ (Die) を1つのパッケージに封入したマルチコア・マルチダイ形式をとり、マルチコア・チップを早く出荷するというアプローチを取った。製品名ではPentium Dなど。近年では逆にAMDが設計の単純なマルチダイのOpteronチップを出荷する一方で、IntelはCPUコアのモジュール化によって派生ダイの製造を容易にし、リングバスの導入によりコア数の増減を容易にしているため、マルチダイの手段を取っていない。
また同じ2005年にはサン・マイクロシステムズはサーバ向けプロセッサUltraSPARC T1で8コアを実現した。
このほかPower Architecture系では、2006年リリースのCellが8コア[2]、2010年リリースのPOWER7が8コアである。
マルチコア・プロセッサの技術
ホモジニアスとヘテロジニアス
同種のコアを複数実装する「ホモジニアスマルチコア」と、異種のコアを実装する「ヘテロジニアスマルチコア」が存在する。
IBM、ソニー・コンピュータエンタテインメント、東芝の3社が共同開発しPlayStation 3に組み込まれているCellプロセッサは、1個の汎用的なプロセッサコアと8個のシンプルなプロセッサコアが組み合わせたヘテロジニアスマルチコアというアプローチをとっている。
Xbox 360のプロセッサ・コアは対称型マルチコアと呼ばれる3コアのプロセッサで、構造上はホモジニアスに属するものである。
米AMD社はさらなる高処理能力化への手法としてヘテロジニアスマルチコアプロセッサを計画し、Fusionプロジェクトと命名した。その手始めとして、グラフィックス処理プロセッサ (GPU) 開発企業のカナダのATI社を2006年に買収し、GPUと汎用プロセッサを同一ダイに集積したCPU製品を登場させた。
また、命令セットの形式が同じコアを組合わせたプロセッサの内、処理能力の高いコアと処理能力が低いコアを組み合わせたプロセッサもトランジスタ数や消費電力の点で有利な低コストのマルチコアと考えられる。同一命令セットという観点ではホモジニアスではあるが、処理能力の点では同一ではなくヘテロジニアスとなる。
電力管理
マルチコア化の目的の1つに低消費電力化がある。マルチコアに限らないが、多くの汎用プロセッサや専用プロセッサでは、使用しないコアのクロックを停止する「クロック・ゲーティング」、機能ブロックごとに電源供給を停止してリーク電流そのものを無くする「パワー・ゲーティング」が備わっている。
汎用プロセッサの中には他のコアを停止する代わりに1つのコアだけ供給電圧やクロックを高めてシングルコアでの処理性能を高める技術も導入が予定されている。機能ブロックごとにスレッシュホールド電圧値を変えて動作速度を変えるのは「マルチVth」と呼ばれる。マルチコアでは、機能ブロックごとでしか行えなかったシングルコア製品よりさらに進んだ電力と処理性能との最適化機能が取り込まれる。
メモリー・ボトルネックの解消
現代のプロセッサはノイマン型であるため、ノイマンズ・ボトルネックによる処理速度の制約がある。2009年現在の主記憶装置に使われるDRAMの速度はプロセッサに比べて極めて遅く、この速度差を解消するメモリ技術は未だに現れていない。
シングルコアでは、プロセッサ内部に小容量のキャッシュメモリを何階層も重ねて持つなど、遅い主記憶装置でもプロセッサの処理性能を大きく損なうことを避けてきたが、複数のプロセッサ・コアを単一の主記憶装置へ接続することは、メモリーアクセスによるボトルネックが顕在化する危険性をはらんでいる。
- 主記憶装置アクセスの高速化
- 代表的なプロセッサ・メーカー2社は、外部(ノースブリッジ)にあったDRAMコントローラーをマルチコア・プロセッサに取り込み、これらのアクセス信号線を高速化するなど主記憶装置への帯域幅を広げることで対応する予定である。
- キャッシュシステムの高度化
- 主記憶装置であるDRAMとプロセッサ側との速度差はマルチコアの採用によって一層拡大するため、シングルコア以上にキャッシュシステムによるメモリ帯域幅の確保は重要となる。
- 幸い、プリフェッチへの努力をある程度あきらめることで、そういった回路へ割いていたトランジスタが削減できてそれぞれのプロセッサ・コアを小さく作れるため、プロセスルールの微細化による恩恵も続くことに合わせて、複数のプロセッサ・コアを1つのダイに載せてもなお、充分な容量のローカルキャッシュを作り込む余裕が生まれる。
- 各コアごとにローカルでキャッシュを持つことはアクセス・スピードでは有利になるが、互いのローカル・キャッシュの内容を同一に保つスヌープ機構が複雑になり、各ローカル・キャッシュを共有し合う機構ではさらに複雑になる[3]。このため、複数のコアの配下で3レベルにもなるキャッシュ階層同士が最適の調停機構を実現するにはこれまでのプリフェッチへの努力とは違った種類の複雑で高速動作が求められる回路がダイの上で大きな面積を占めるようになる。この新たなキャッシュコントローラー部はかなり電力を消費するが、少しでも主記憶装置への無駄なアクセスが減らせるのであれば消費電力は総合的には削減できるとされる。
冗長構成
メモリー半導体ではあらかじめ冗長領域を設けて不良を少なくする工夫が行われているが、マルチコアの登場によって演算部であるコアも同様の冗長的な編成が可能となっている。ソニー・コンピュータエンタテインメントのCellプロセッサでは8個あるコア相当のSPEの内、実際にイネーブルにするSPEは7個とした。こうすることで1個のSPEの動作不良な量産ダイの中でも出荷可能となり、歩留まりが向上する。米インテル社から将来出荷予定のNehalemでもキャッシュメモリーの冗長化だけでなく不良コアをディスエーブルする機能が付くと公表されている。
プロセッサ例
汎用プロセッサ
- IBMのPOWER4、POWER5、POWER6、POWER7
- サン・マイクロシステムズのRock
富士通のSPARC64 VII- AMDのAthlon X2、Phenom II、Opteron、Zen
- インテルの現行製品の系列であるNehalem、Sandy Bridge、Ivy Bridge、Haswellマイクロアーキテクチャ、Broadwellマイクロアーキテクチャ、Skylakeマイクロアーキテクチャ、Kaby Lakeマイクロアーキテクチャ、Coffee Lakeマイクロアーキテクチャ。インテルの過去の製品であるTukwila
- ICTのGodson-3
なお、インテルは10個以上のコアを集積したプロセッサをメニーコアと呼んでいる[1]。
専用プロセッサ
- インテルのLarrabee - 16個
シスコシステムズのQFPネットワーク・プロセッサ - 40個- D. E. Shaw ResearchのAnton
トプスシステムズのTOPSTREAM - 最初からマルチコア向けに開発された日本製プロセッサ、MPEG4およびWirelessLANのベースバント処理チップの実績あり
- 組み込み系プロセッサ
- 汎用プロセッサでマルチコアが一般化する以前から、組み込みシステムではマルチコアは一般的に使われている。iPodに搭載されているPortalPlayerのチップは、「ARM7」のコアを2つ搭載している。
注釈
- ^ abインテル、メニーコア化への取り組みなど、研究活動に関する説明会を開催, マイコミジャーナル, 2005年11月09日
^ 設計上は9コアが存在するが、うち1コアは歩留まり向上のための予備であり、出荷前に無効とされている。
^ ローカル・キャッシュを共有し合う機構とは、コアローカルなL2キャッシュとダイ共有のL3キャッシュの関係で、通常はスヌープしてローカルなL2キャッシュ間のコヒーレンシを確保する仕組みである。自分のコアのL2でmissして他のコアのL2にあれば、L3ではなく他のコアのL2をアクセスする仕組みを指す。コア数が増えるとダイ共有のL3では対応し切れなくなる為と推測される。
関連項目
- 対称型マルチプロセッシング
- 同時マルチスレッディング
| ||||||||||||||||||||||||


